Tôi thường phải tạo các ô xếp chồng xếp chồng để so sánh các biến, và vì tôi làm tất cả các chỉ số của mình trong R, tôi thích làm tất cả đồ họa của mình trong R với ggplot2. Tôi muốn tìm hiểu cách thực hiện hai việc:Làm cách nào để tạo biểu đồ thanh xếp chồng lên nhau tốt hơn với nhiều biến từ ggplot2?
Trước tiên, tôi muốn có thể thêm dấu tỷ lệ phần trăm thích hợp cho mỗi biến thay vì đánh dấu bằng số. Số lượng sẽ gây nhầm lẫn, đó là lý do tại sao tôi đưa ra các nhãn trục hoàn toàn.
Thứ hai, phải có cách đơn giản hơn để tổ chức lại dữ liệu của tôi để thực hiện điều này. Nó có vẻ như là loại điều tôi sẽ có thể làm tự nhiên trong ggplot2 với plyR, nhưng tài liệu cho plyR không phải là rất rõ ràng (và tôi đã đọc cả sách ggplot2 và tài liệu plyR trực tuyến.
Biểu đồ tốt nhất của tôi trông như thế này, các mã để tạo ra nó sau:
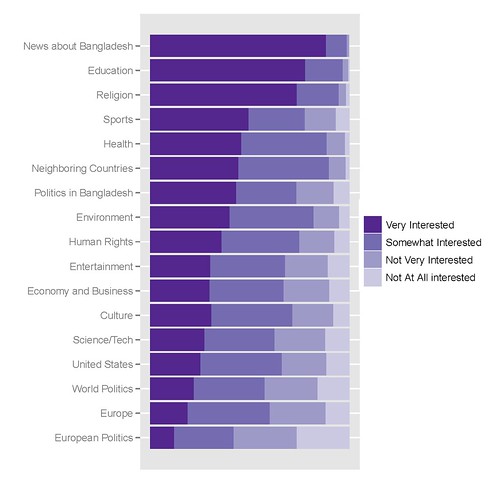
mã R tôi sử dụng để có được nó là như sau:
library(epicalc)
### recode the variables to factors ###
recode(c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ), c(1,2,3,4,5,6,7,8,9, NA),
c('Very Interested','Somewhat Interested','Not Very Interested','Not At All interested',NA,NA,NA,NA,NA,NA))
### Combine recoded variables to a common vector
Interest1<-c(int_newcoun, int_newneigh, int_neweur, int_newusa, int_neweco, int_newit, int_newen, int_newsp, int_newhr, int_newlit, int_newent, int_newrel, int_newhth, int_bapo, int_wopo, int_eupo, int_educ)
### Create a second vector to label the first vector by original variable ###
a1<-rep("News about Bangladesh", length(int_newcoun))
a2<-rep("Neighboring Countries", length(int_newneigh))
[...]
a17<-rep("Education", length(int_educ))
Interest2<-c(a1, a2, a3, a4, a5, a6, a7, a8, a9, a10, a11, a12, a13, a14, a15, a16, a17)
### Create a Weighting vector of the proper length ###
Interest.weight<-rep(weight, 17)
### Make and save a new data frame from the three vectors ###
Interest.df<-cbind(Interest1, Interest2, Interest.weight)
Interest.df<-as.data.frame(Interest.df)
write.csv(Interest.df, 'C:\\Documents and Settings\\[name]\\Desktop\\Sweave\\InterestBangladesh.csv')
### Sort the factor levels to display properly ###
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Not Very Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Somewhat Interested')
Interest.df$Interest1<-relevel(Interest$Interest1, ref='Very Interested')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='News about Bangladesh')
Interest.df$Interest2<-relevel(Interest$Interest2, ref='Education')
[...]
Interest.df$Interest2<-relevel(Interest$Interest2, ref='European Politics')
detach(Interest)
attach(Interest)
### Finally create the graph in ggplot2 ###
library(ggplot2)
p<-ggplot(Interest, aes(Interest2, ..count..))
p<-p+geom_bar((aes(weight=Interest.weight, fill=Interest1)))
p<-p+coord_flip()
p<-p+scale_y_continuous("", breaks=NA)
p<-p+scale_fill_manual(value = rev(brewer.pal(5, "Purples")))
p
update_labels(p, list(fill='', x='', y=''))
tôi muốn rất nhiều đánh giá cao bất cứ lời khuyên, thủ thuật hay gợi ý.
{kind=link}
Thay vì 'relevel' nhiều lần bạn có thể sử dụng một lần' yếu tố' bằng đối số 'nhãn'. Bạn cũng có thể kiểm tra 'sắp xếp lại' có thể sắp xếp các mức của bạn bằng một số biến (phần trăm" rất quan tâm "?) – Marek
Màu sắc đẹp - nghĩ rằng tôi sẽ sử dụng các mẫu bia của tôi một ngày :-) – Andreas
Bạn có muốn một luồng công việc sản xuất dữ liệu đi vào một biểu đồ như vậy cộng với có thể thêm các giá trị phần trăm trên đầu trang của mỗi nhóm điền vào mỗi thanh? – Jay