NVIDIA cung cấp GPUDirect để giảm chi phí chuyển bộ nhớ. Tôi tự hỏi nếu có một khái niệm tương tự cho AMD/ATI? Cụ thể:OpenCL của AMD có cung cấp cái gì đó tương tự như GPUDirect của CUDA không?
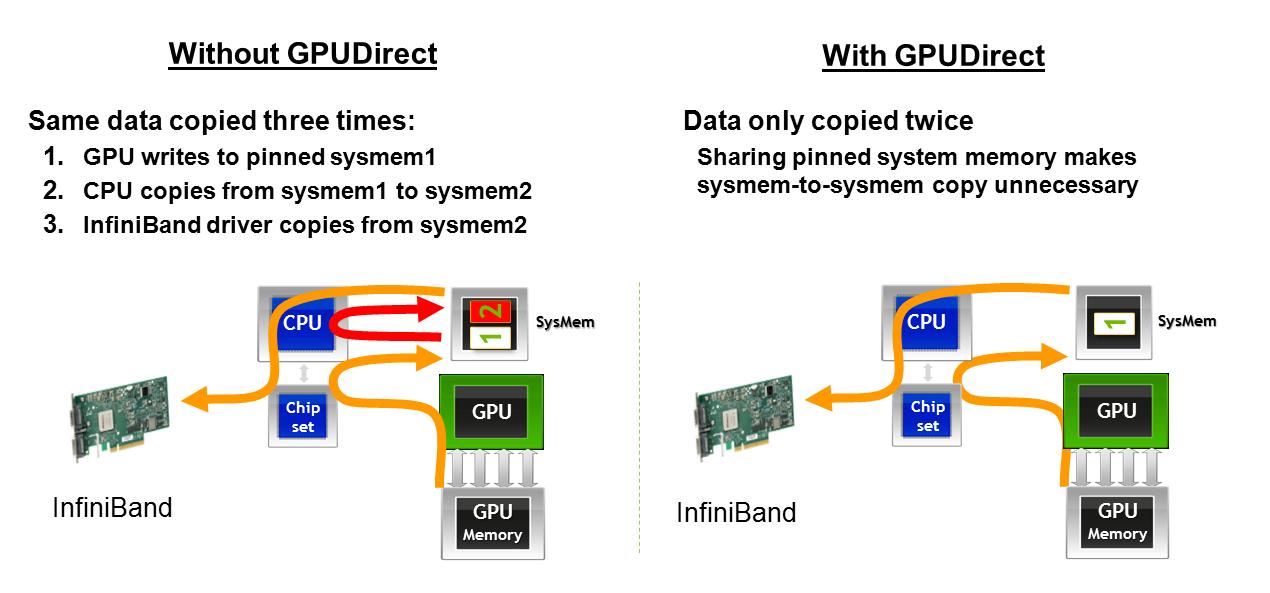
1) Làm GPU AMD tránh chuyển giao bộ nhớ thứ hai khi giao tiếp với thẻ mạng, as described here. Trong trường hợp đồ họa bị mất tại một số điểm, dưới đây là mô tả về tác động của GPUDirect đối với việc lấy dữ liệu từ GPU trên một máy được truyền qua giao diện mạng: Với GPUDirect, bộ nhớ GPU sẽ chuyển tới bộ nhớ Máy chủ rồi chuyển thẳng tới mạng Thẻ giao diện. Nếu không có GPUDirect, bộ nhớ GPU sẽ chuyển đến bộ nhớ Máy chủ trong một không gian địa chỉ, sau đó CPU phải sao chép để lấy bộ nhớ vào một không gian địa chỉ bộ nhớ Máy chủ khác, sau đó nó có thể chuyển sang thẻ mạng.
{kind=link}
2) GPU AMD cho phép chuyển giao bộ nhớ P2P khi hai GPU được chia sẻ trên cùng một bus PCIe, as described here. Trong trường hợp đồ họa bị mất tại một số điểm, đây là mô tả về tác động của GPUDirect khi truyền dữ liệu giữa các GPU trên cùng một bus PCIe: Với GPUDirect, dữ liệu có thể di chuyển trực tiếp giữa các GPU trên cùng một bus PCIe mà không cần chạm vào bộ nhớ máy chủ. Nếu không có GPUDirect, dữ liệu luôn phải quay trở lại máy chủ trước khi nó có thể đến GPU khác, bất kể vị trí của GPU đó.
{kind=link}
Chỉnh sửa: BTW, tôi không hoàn toàn chắc chắn bao nhiêu phần mềm GPUDirect là phần mềm độc hại và bao nhiêu phần mềm thực sự hữu ích. Tôi đã không bao giờ thực sự nghe nói về một lập trình GPU sử dụng nó cho một cái gì đó thực sự. Suy nghĩ về điều này được chào đón quá.
Ông có thể cung cấp một mô tả văn bản của hai công nghệ trong trường hợp đồ họa liên quan được đưa xuống tại một số ngày sau đó? Ngoài ra, tôi thấy đồ họa thứ hai không rõ ràng về những gì được cung cấp. – James
James, điều này được thực hiện. – arrayfire
@gpu: mvapich2 có hỗ trợ trực tiếp GPU trong bản phát hành gần đây, tôi đã sử dụng nó và nó thực sự nhanh hơn - bạn có thể gọi 'MPI_Send' và' MPI_recv' và chuyển con trỏ bộ nhớ GPU làm đối số và mọi thứ "chỉ hoạt động". – talonmies