Tôi đang viết một thuật toán trong OpenCL, trong đó tôi cần mọi đơn vị công việc để ghi nhớ một phần dữ liệu hợp lý, nói điều gì đó giữa long[70] và long[200] hoặc hạt nhân.bộ nhớ vật lý trên các thiết bị AMD: cục bộ và riêng
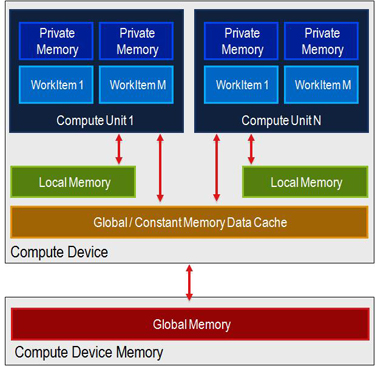
Thiết bị AMD gần đây có 32 bộ nhớ KiB __local, tức là (cho số lượng dữ liệu nhất định cho mỗi hạt nhân) đủ để lưu trữ thông tin cho 20-58 đơn vị làm việc. Tuy nhiên, từ những gì tôi hiểu từ kiến trúc (và đặc biệt là từ this drawing), mỗi lõi của trình đổ bóng cũng có một lượng bộ nhớ riêng. Tuy nhiên tôi không tìm thấy kích thước của nó.
{kind=link}
Bất cứ ai có thể cho tôi biết làm thế nào để tìm ra bao nhiêu bộ nhớ riêng mỗi hạt nhân có?
Tôi đặc biệt tò mò về HD7970, vì tôi dự định mua một số trong số này sớm.
Edit: Giải quyết vấn đề, câu trả lời là here trong phụ lục D.
Tôi không tin rằng bộ nhớ riêng được dành riêng cho mỗi lõi - nó ánh xạ tới tệp đăng ký, mỗi tài nguyên đơn vị tính toán. Mỗi mục công việc được đăng ký được cấp phát từ tệp đăng ký đơn vị tính toán, số lượng được yêu cầu xác định số lượng wavefront trong chuyến bay tại bất kỳ thời điểm nào đã cho. – talonmies
Từ bản vẽ nổi tiếng khắp mọi nơi http://www.codeproject.com/KB/showcase/Memory-Spaces/image001.jpg Tôi kết luận rằng bộ nhớ riêng có thể chất khác với bộ nhớ __local, phải không? – user1111929
Có, chúng khác nhau về thể chất. Bộ nhớ riêng ánh xạ tới tập tin đăng ký đơn vị tính toán, bộ nhớ cục bộ để tính bộ nhớ chia sẻ mức đơn vị trong hầu hết các thiết bị AMD hiện đại. Một vài GPU tương thích OpenCL sớm không có bộ nhớ chia sẻ chết và bộ nhớ cục bộ chỉ là SDRAM. Không phải là mỗi lõi và số lượng bạn sử dụng cho mỗi mục công việc cho nhóm riêng tư và mỗi nhóm làm việc cho các hiệu ứng cục bộ số lượng các wavefront đồng thời chạy trên mỗi đơn vị tính toán. – talonmies