Đối với một trong các dự án khóa học của tôi, tôi bắt đầu thực hiện "Naive Bayesian classifier" trong C. Dự án của tôi là triển khai ứng dụng trình phân loại tài liệu (đặc biệt là Spam).Vấn đề với hoạt động điểm chính xác trong C
Bây giờ tôi gặp sự cố khi triển khai thuật toán vì các hạn chế trong kiểu dữ liệu của C.
(Algorithm Tôi đang sử dụng được đưa ra ở đây, http://en.wikipedia.org/wiki/Bayesian_spam_filtering)
VẤN ĐỀ BÁO CÁO: Thuật toán bao gồm việc uống mỗi từ trong một tài liệu và tính toán khả năng nó là từ thư rác. Nếu p1, p2 p3 .... pn là xác suất của từ-1, 2, 3 ... n. Xác suất của doc là spam hoặc không được tính bằng

Ở đây, giá trị xác suất có thể rất dễ dàng xung quanh 0,01. Vì vậy, ngay cả khi tôi sử dụng datatype "gấp đôi" tính toán của tôi sẽ đi cho một quăng. Để xác nhận điều này tôi đã viết một mã mẫu được đưa ra dưới đây.
#define PROBABILITY_OF_UNLIKELY_SPAM_WORD (0.01)
#define PROBABILITY_OF_MOSTLY_SPAM_WORD (0.99)
int main()
{
int index;
long double numerator = 1.0;
long double denom1 = 1.0, denom2 = 1.0;
long double doc_spam_prob;
/* Simulating FEW unlikely spam words */
for(index = 0; index < 162; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_UNLIKELY_SPAM_WORD;
denom1 = denom1*(long double)(1 - PROBABILITY_OF_UNLIKELY_SPAM_WORD);
}
/* Simulating lot of mostly definite spam words */
for (index = 0; index < 1000; index++)
{
numerator = numerator*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom2 = denom2*(long double)PROBABILITY_OF_MOSTLY_SPAM_WORD;
denom1 = denom1*(long double)(1- PROBABILITY_OF_MOSTLY_SPAM_WORD);
}
doc_spam_prob= (numerator/(denom1+denom2));
return 0;
}
Tôi đã thử các kiểu dữ liệu kép nổi, đôi và thậm chí dài nhưng vẫn gặp vấn đề tương tự.
Do đó, hãy nói trong tài liệu 100K từ tôi đang phân tích, nếu chỉ 162 từ có xác suất spam 1% và 99838 là từ spam rõ ràng, thì ứng dụng của tôi sẽ nói là Không phải spam vì lỗi chính xác (như tử số dễ dàng đi đến ZERO) !!!.
Đây là lần đầu tiên tôi gặp sự cố như vậy. Vậy vấn đề này sẽ được giải quyết như thế nào?

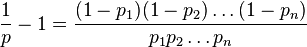



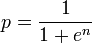
+1. Tôi đã cập nhật câu trả lời của mình. Tôi nghĩ tốt nhất là kết hợp cả hai thuật toán, vì tôi bị mất chính xác ít hơn để tính toán các yếu tố và số tiền của bạn ít hơn để tính tổng sản phẩm. – back2dos